Can Word2Vec Describe Art-Historical Categories?
2020-07-04
word2vec, quackery, the-curator, art
Part One: Gathering Data
Last year, after reading some papers on the subject, I got excited about Word2Vec and GLoVE. Researchers were using large bodies of text — for example, from Google News and Wikipedia — to train models, which could predict the next word following a sequence of words, or describe analogies, such as “Paris is to France as Berlin is to X”, where the model accurately predicts X is “Germany.”1
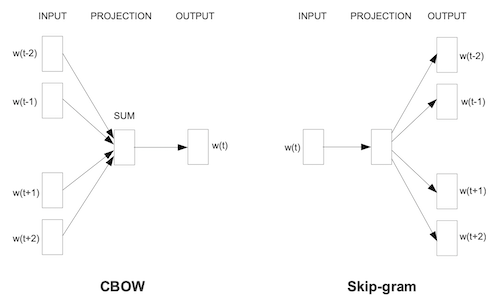
I read that Word2Vec analyzes documents in two modes: bag-of-words and skip-gram. Both modes define a default context window of five words. In bag-of-words mode, the model starts with [a, b, d, e] and tries to predict c, while skip-gram goes in the opposite direction, taking c and trying to predict [a, b, d, e].
One way to look at this is that, within the context window, words are equally related. Take this sentence from Hamlet:
'To be or not to be that is the question'
If we were to slide a context window across Shakespeare’s ten famous words, they would be split into two groups of five words each2:
# group A
['to', 'be', 'or', 'not', 'to']
# group B
['be', 'that', 'is', 'the', 'question']
Since the terms within a context window are equally related, rearranging the order of those terms is arbitrary. So the following two groups are equal to the previous two.
# group A
['be', 'not', 'or', 'to', 'to']
# group B
['question', 'the', 'is', 'that', 'be']
Therefore, the context window can be thought about as a complete graph, where each node connects to all the other nodes.
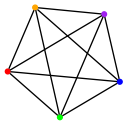
So while I was sliding context windows across sentences, I wondered, what if a corpus exploited the context window but wasn’t a corpus of sequential sentences, or even sentences at all? What if it was a graph?
I can’t pinpoint exactly what it is about network graphs that fascinate me, but they are one of my favorite structures. Is there a more elegant way to describe relationships between two or more things? Network graphs can map out everything from the bridges of Königsberg to associations between memories. If you love graphs, then you know what I’m talking about.
At some point I downloaded the exhibition data from the Museum of Modern Art (MoMA). Data is something else that fascinates me. Rationally, I know that most people don’t share my fascination of huge datasets. But deep down, I don’t understand how they could not.
Naturally, a graph describes MoMA’s exhibition data. Here is the exhibition titled “Five Unrelated Photographers”, number 723.
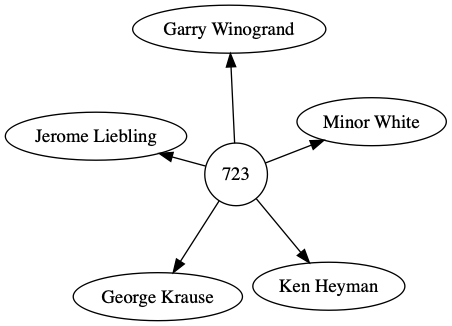
Each exhibition points to its members, in this example five. From the point of view of the exhibition, each member is equally related. That is, we could also represent “Five Unrelated Photographers” as a K5 complete graph, which is the same graph as the context window. So this exhibition could also be represented in a context window!
['kenheyman', 'georgekrause', 'jeromeliebling', 'minorwhite', 'garrywinogrand']
Because the count of artists is equal to the size of the context window, Word2Vec will recognize this as a group of equally related terms.
But what about exhibitions where the member count is greater than the size of the context window?
Python has a great standard module called itertools, which includes functions for combinations and permutations. For this purpose, the order of terms is arbitrary, so combinations is the function to use. Given an exhibition of N terms and an r-length equal to the size of the context window, combinations produces a list of all possible combinations.
>>> from itertools import combinations
>>> combos = combinations(range(6), 5)
>>> [x for x in combos]
[
(0, 1, 2, 3, 4),
(0, 1, 2, 3, 5),
(0, 1, 2, 4, 5),
(0, 1, 3, 4, 5),
(0, 2, 3, 4, 5),
(1, 2, 3, 4, 5)
]
From this results the building blocks for a new dataset that can be fed into Word2Vec. A sample of the resulting dataset looks like this:
...
peggibacon paulgauloi charlgoeller arshilgorki annweaver
peggibacon paulgauloi charlgoeller stefanhirsch hokeah
peggibacon paulgauloi charlgoeller stefanhirsch ruthjona
...
The big question is, for now, left unanswered. Whether or not, the model can describe art historical movements and disprove the null hypothesis is the topic for future posts. But first, I need a way to visualize the model’s results and to measure the error rate.
Footnote
This is a great talk by Rachel Thomas, who explains word embeddings and also goes into the biases they can encode.
Up### This is an extreme simplification of how the context window proceeds. It actually iterates across a sentence word by word. {#date}
WORD --> WINDOW
----------------------------------
to --> ['be', 'or', 'not']
be --> ['to', 'or', 'not', 'to']
or --> ['to', 'be', 'not', 'to', 'be']
not --> ['to', 'be', 'or', 'to', 'be', 'that']
to --> ['be', 'or', 'not', 'be', 'that', 'is']
be --> ['or', 'not', 'to', 'that', 'is', 'the']
that --> ['not', 'to', 'be', 'is', 'the', 'question']
is --> ['to', 'be', 'that', 'the', 'question']
the --> ['be', 'that', 'is', 'question']
question --> ['that', 'is', 'the']