“Exhibition Autocomplete: Displaying imagesets from The Curator”
2020-09-05
word2vec, imagesets, webapps
In the last three posts I focused on the data side of a personal project, The Curator. For this post, I’ll quickly document the web interface that I’m calling Exhibition Autocomplete.
The basic user experience is:
- Begin typing and select a term from the autocomplete list;
- Browse a collection of images;
- Rinse and repeat.

Maybe it’s because I built it, but the interface is a pleasure to play around with. The collections are composed of beautiful images that seem to fit together.
The model deployed, 1.8.2, has a 73% error rate for predicting a similar artist within the same art historical category. Though the error rate is higher than 50%, the image collections do not look random to my eye. That is, Impressionists are not too mixed up with Minimalists and Conceptualists.
The dataflow works something like the following figure illustrates.
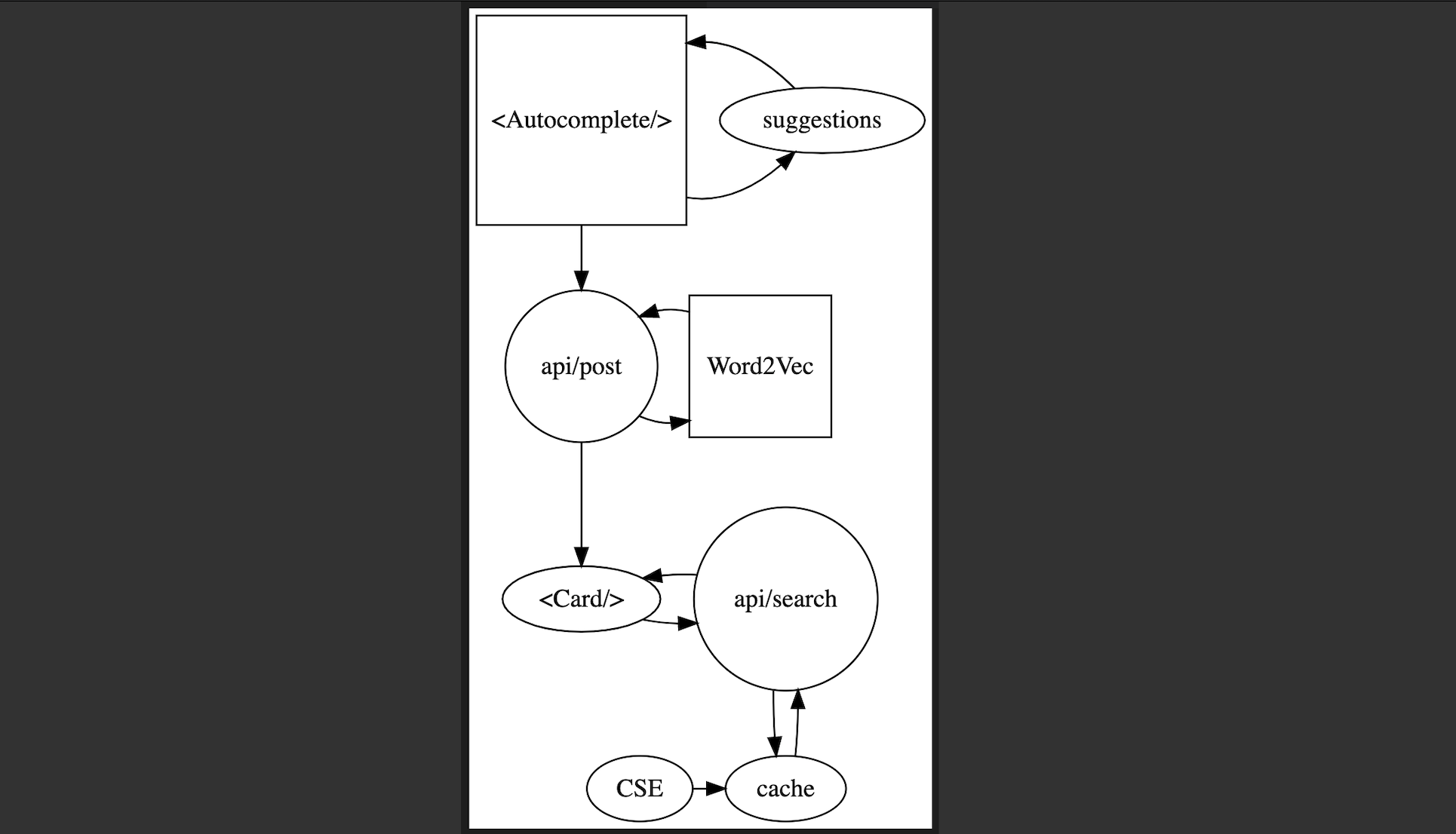
The python model is pretty slow. But all the outputs from this call can be memoized, so convenience is the only reason to use the python model instead of a lookup table in this case.
> time python python/resolver.py "Pablo Picasso"
{"name": "Pablo Picasso", "artists": ["Henri Matisse", "Amedeo Modigliani", "Alberto Giacometti", "Raoul Dufy", "Franti\u009aek Kupka", "Lovis Corinth", "Alexander Calder", "Henry Moore", "Odilon Redon", "Ernst Ludwig Kirchner", "Jules Pascin", "Auguste Rodin"]}
python python/resolver.py "Pablo Picasso" 0.79s user 0.21s system 69% cpu 1.461 total
Anyway, not sure yet if I’ll publish the site online. The images are gathered from a Google custom search engine, which restricts free accounts to a low quota. I got around this by writing a really simple cache.
// Attempt to get a cached result.
getCachedResult(name, (err, cache) => {
// If one isn't found submit a search request.
if (err) {
search(name, serverRuntimeConfig)
.then((data) => {
if (data.error) {
res.json(data);
} else {
// Cache the search results.
setCachedResult(name, data);
res.json(data.items[0]);
}
})
.catch((err) => {
res.json({ error: err });
});
} else {
// Otherwise, return the existing cache data.
res.json(JSON.parse(cache).items[0]);
}
});
So, with a lookup table, loading animations and a more sophisticated cache, it would be possible to go live…